dataframe常用操作方式
作者:高景洋 日期:2020-11-13 15:33:11 浏览次数:1468
下边用示例代码,给大家做个演示,并针输出结果截图。
from pyspark import SparkContext,SparkConf
from pyspark.sql.session import SparkSession
from pyspark.sql.types import StructField, StructType, StringType
if __name__ == '__main__': spark = SparkSession.builder.master("local").appName("SparkOnHive").getOrCreate()#.enableHiveSupport()
schema = StructType([
# true代表不为空
StructField("WebsiteID", StringType(), True),
StructField("Url", StringType(), True),
StructField("IsDeleted", StringType(), True),
StructField("IsThirdPartySaler", StringType(), True),
StructField("JobHistory", StringType(), True),
StructField("RowKey", StringType(), True) ]) df = spark.read.csv('file:///Users/jasongao/Documents/tmp/hbase-0.csv',schema)
# 显示dataframe数据,show方法不加具体数值,默认显示20条数据
df.show()

# 显示特定列
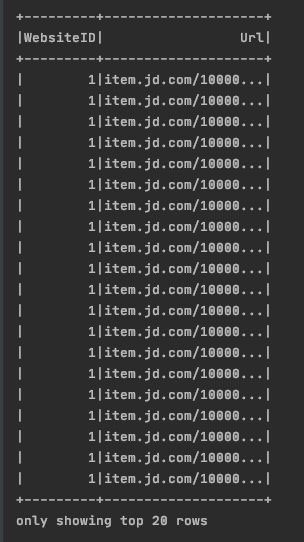
df.select('WebsiteID','Url').show()
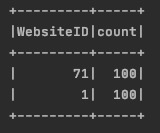
# 按指定字段做groupby 操作
df.groupby('WebsiteID').count().show()
# 精确查询
df.filter(df['Url']=='item.jd.com/100000181227.html').show()

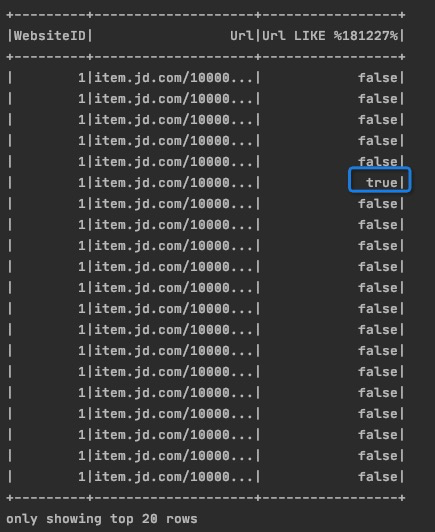
# 模糊查询,会显示所有数据,在最后补增列显示匹配结果
df.select('WebsiteID','Url',df['Url'].like('%181227%')).show()
# sql 查询方式,使查询更容易理解
df.registerTempTable('Product') spark.sql("select * from Product where Url ='item.jd.com/100000181227.html'").show()
spark.stop()

本文永久性链接:
<a href="http://r4.com.cn/art162.aspx">dataframe常用操作方式</a>
<a href="http://r4.com.cn/art162.aspx">dataframe常用操作方式</a>
当前header:Host: r4.com.cn
X-Host1: r4.com.cn
X-Host2: r4.com.cn
X-Host3: 127.0.0.1:8080
X-Forwarded-For: 3.140.185.123
X-Real-Ip: 3.140.185.123
X-Domain: r4.com.cn
X-Request: GET /art162.aspx HTTP/1.1
X-Request-Uri: /art162.aspx
Connection: close
Accept: */*
User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Referer: http://www.yuezhiji.net/art162.aspx